
Makine öğrenmesi, görüntü tanıma, spam algılama, doğal konuşma anlama, ürün önerileri ve tıbbi teşhisler sunmak için yıllarca kullanılmaktadır. Günümüzde, makine öğrenme algoritmaları siber güvenliği geliştirmemize, kamu güvenliğini sağlamamıza ve tıbbi sonuçları iyileştirmemize yardımcı olabilir. Makine öğrenim sistemleri ayrıca müşteri hizmetlerini daha iyi ve otomobilleri daha güvenli hale getirebilir.
Makine öğrenmeyi denemeye başladığımda, gerçek dünyadaki bir sorunu çözecek, ancak uygulamak için çok karmaşık olmayacak bir uygulama bulmak istedim. Ayrıca regresyon algoritmalarıyla çalışmayı da pratik yapmak istedim. Böylece çözülmeye değer bir problem aramaya başladım. İşte benim geldiğim şey.
Bir ev satacaksanız, hangi fiyat etiketini koyacağınızı bilmeniz gerekir. Ve bir bilgisayar algoritması size doğru bir tahmin verebilir!
Bu yazıda, ev fiyatlarını tahmin etmek için nasıl bir regresyon algoritması yazdığımı göstereceğim.
Özetle regresyon
Basitçe söylemek gerekirse, regresyon, mevcut istatistiksel verilerden, hedef parametreniz ile bir dizi başka parametre arasındaki ilişkileri öğrenerek tahminler yapmanıza yardımcı olan bir makine öğrenme aracıdır. Bu tanıma göre, bir evin fiyatı yatak odası sayısı, yaşam alanı, konum vb. Gibi parametrelere bağlıdır. Bu parametrelere yapay öğrenme uygularsak, belirli bir coğrafi alanda ev değerlerini hesaplayabiliriz.
Regresyon fikri oldukça basittir: Yeterli veri verildiğinde, hedef parametreniz (çıktı) ve diğer parametreler (girdi) arasındaki ilişkiyi gözlemleyebilir ve daha sonra bu ilişki işlevini gerçek gözlemlenen verilere uygulayabilirsiniz.
Regresyon algoritmasının nasıl çalıştığını göstermek için fiyatı tahmin etmek için yalnızca bir parametreyi (bir evin yaşam alanı) dikkate alacağız. Alan ve fiyat arasında doğrusal bir ilişki olduğunu varsaymak mantıklıdır. Liseden hatırladığımız gibi, doğrusal bir ilişki doğrusal bir denklemle temsil edilir:
y = k0 + k1 * x
Bizim durumumuzda, y , fiyata eşittir ve x , alana eşittir. Bir evin fiyatını tahmin etmek denklemi çözmek kadar basittir ( k0 ve k1'in sabit katsayılar olduğu yerler):
fiyat = k0 + k1 * alan
Regresyon kullanarak bu katsayıları ( k0 ve k1 ) hesaplayabiliriz . Belirli bir alanda 1000 bilinen ev fiyatımız olduğunu varsayalım. Bir öğrenme tekniği kullanarak, bir dizi katsayı değeri bulabiliriz. Bulduktan sonra, ortaya çıkan fiyatı tahmin etmek için farklı alan değerlerini girebiliriz.
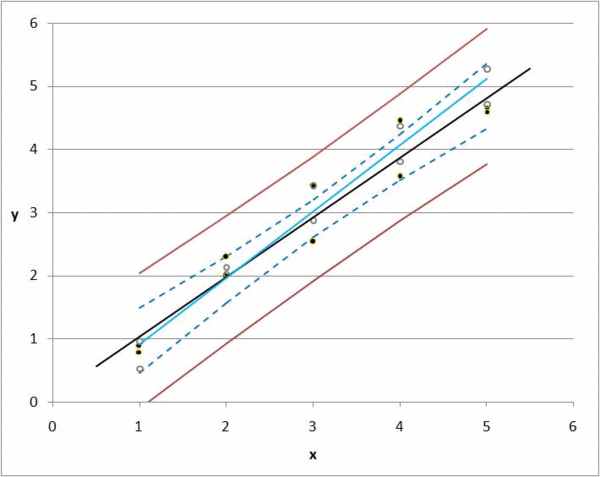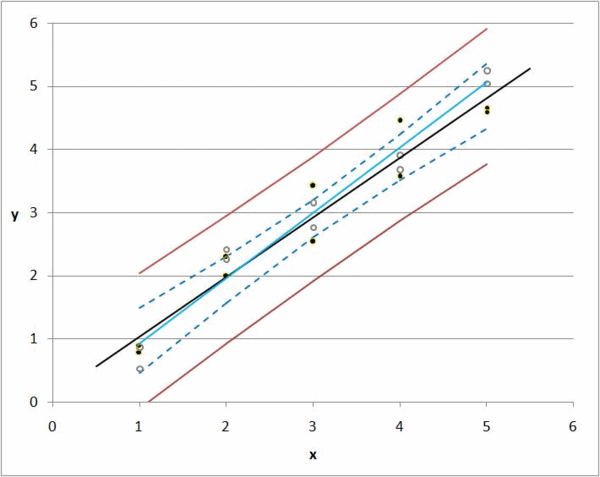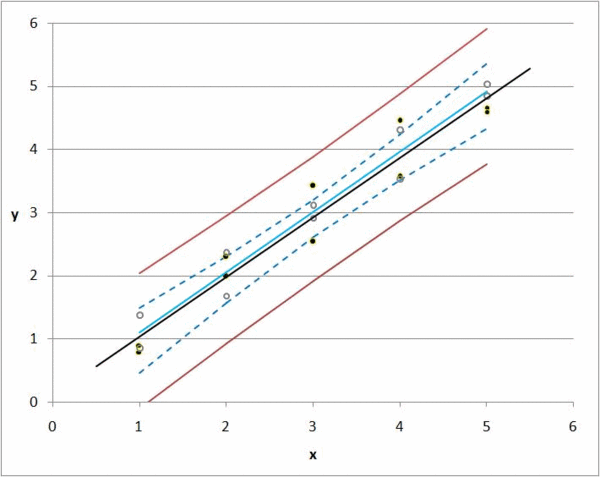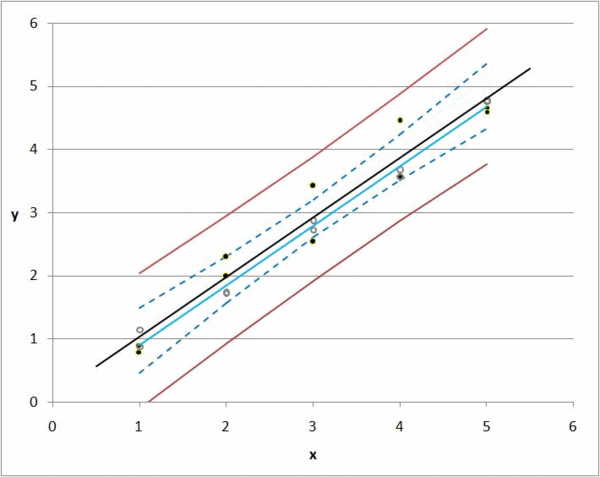
[Bu grafikte, y fiyat ve x yaşam alanıdır. Siyah noktalar bizim gözlemlerimiz. Hareketli çizgiler k0 ve k1değiştiğinde ne olacağını gösterir .
Ancak, öngörülen bir değer ile gerçek değer arasında daima bir sapma veya fark vardır. 1000 gözlemimiz varsa, her bir k0 ve k1 kombinasyonunun sapmalarını toplayarak tüm maddelerin toplam sapmasını hesaplayabiliriz .
Regresyon k0 ve k1 için mümkün olan her değeri alır ve toplam sapmayı en aza indirir; Bu kısaca regresyon fikridir.
Fakat gerçek hayatta başa çıkmanız gereken başka zorluklar var. Konut fiyatları belli ki birden fazla parametreye bağlı ve bu parametrelerin tümü arasında net bir doğrusal ilişki yok.
Şimdi size projede konut fiyatını tahmin etmek için regresyon algoritmalarını nasıl kullandığımı anlatacağım.
Makine öğrenmesinde regresyon algoritmaları nasıl kullanılır?
1. Veri topla
Her türlü makine öğrenmesi analizi için ilk adım, verilerin toplanmasıdır - geçerli olması gereken. Verilerinizin geçerliliğini garanti edemezseniz, o zaman analiz etmenin bir anlamı yoktur. Verilerinizi aldığınız kaynağa dikkat etmeniz gerekir.
Amaçlarım için, Sakarya'daki en büyük emlak portallarından birinin veritabanına güvenmiştim. Sakarya'daki emlak piyasası sıkı bir şekilde düzenlendiğinden, geçerliliğini kontrol etmek zorunda değildim.
Başlangıçta bazı veri madenciliği yapmak zorunda kaldım, çünkü gerekli veriler çoklu kaynaklarda çeşitli formatlarda mevcuttu. Gerçek dünyadaki çoğu projede bazı veri madenciliği de yapmanız gerekecektir. Bununla birlikte burada veri madenciliğini tartışmayacağız, çünkü konu ile gerçekten ilgili değil.
Bu makalenin amacı doğrultusunda, bulduğum tüm emlak verilerinin aşağıda gösterilen formatta olduğunu düşünelim.
2. Verileri analiz edin
Verileri topladığınızda, analiz etme zamanı gelmiştir. Verileri ayrıştırdıktan sonra aşağıdaki kayıtları aldım:
-
{"has_garden": 1, "years": 1980, "lng": 4.640685, "has_garage": 0, "number_of_changes": "2", "area": 127, "bedrooms_count": "4", "com_time" : 57, "price": 305000, "energy_label": 1, "lat": 52.30177, "rooms_count": "5", "life_quality": 6, "house_type": 1, "is_leasehold": 0}
-
{"has_garden": 1, "years": 1980, "lng": 4.656503, "has_garage": 0, "number_of_changes": "3", "area": 106, "bedrooms_count": "3", "com_time" : 64, "price": 275000, "energy_label": 3, "lat": 52.35456, "rooms_count": "4", "life_quality": 5, "house_type": 1, "is_leasehold": 0}
-
{"has_garden": 1, "years": 1980, "lng": 4.585596, "has_garage": 0, "number_of_changes": "3", "area": 106, "bedrooms_count": "3", "com_time" : 74, "price": 244000, "energy_label": 3, "lat": 52.29309, "rooms_count": "4", "life_quality": 6, "house_type": 1, "is_leasehold": 0}
-
{"has_garden": 1, "years": 1980, "lng": 4.665817, "has_garage": 0, "number_of_changes": "2", "area": 102, " bedrooms_count": "4", "com_time" : 77, "price": 199900, "energy_label": 3, "lat": 52.14919, "rooms_count": "5", "life_quality": 6, "house_type": 1, "is_leasehold": 0}
-
{"has_garden": 1, "years": 1980, "lng": 4.620336, "has_garage": 0, "number_of_changes": "1", "area": 171, "bedrooms_count": "3", "com_time" : 79, "price": 319000, "energy_label": 1, "lat": 52.27822, "rooms_count": "4", "life_quality": 6, "house_type": 1, "is_leasehold": 0}
-
{"has_garden": 1, "years": 1980, "lng": 5.062804, "has_garage": 1, "number_of_changes": "1", "area": 139, "bedrooms_count": "5", "com_time" : 38, "price": 265000, "energy_label": 5, "lat": 52.32992, "rooms_count": "6", "life_quality": 7, "house_type": 1, "is_leasehold": 0}
-
{"has_garden": 1, "years": 1980, "lng": 5.154957, "has_garage": 1, "number_of_changes": "2", "area": 129, "bedrooms_count": "4", "com_time" : 57, "price": 309500, "energy_label": 1, "lat": 52.35634, "rooms_count": "5", "life_quality": 6, "house_type": 1, "is_leasehold": 0}
-
{"has_garden": 1, "years": 1980, "lng": 4.622486, "has_garage": 0, "number_of_changes": "1", "area": 125, "bedrooms_count": "4", "com_time" : 76, "price": 289000, "energy_label": 1, "lat": 52.2818, "rooms_count": "5", "life_quality": 6, "house_type": 1, "is_leasehold": 0}
İşte alanların anlamı:
-
has_garden - mülkün bahçesi var mı? 1 - doğru, 0 - yanlış
-
years - inşaat yılı
-
lat, lng - ev konum koordinatları
-
area- toplam yaşam alanı
-
has_garage - mülkün garajı var mı? 1 - doğru, 0 - yanlış
-
bedrooms_count - yatak odası sayısı
-
rooms_count - toplam oda sayısı
-
energy_label - enerji verimliliği etiketi (Sakarya'daki her ev için atanmıştır)
-
life_quality - her bölge için yerel otoriteler tarafından hesaplanan yaşam kalitesi işareti
-
house_type - emlak tipi (1 - ev, 0 - daire)
-
com_time - Sakarya merkezine gidip gelme süresi
-
changes_count - toplu taşıma araçları ile Sakarya merkezine giderseniz ulaşım değişiklikleri sayılır
Bunların hepsinin bir evin fiyatını etkileyen ölçülebilir veriler olduğu varsayımı üzerinde çalıştım. Tabii ki, ev durumu ve konumu gibi önemli olan daha fazla parametre olabilir. Ancak bu parametreler daha özneldir ve ölçülmesi neredeyse imkansızdır, bu yüzden onları görmezden geldim.
3. Parametreler arasındaki korelasyonu kontrol edin
Şimdi, verilen parametreler arasındaki güçlü korelasyonları kontrol etmeniz gerekir. Varsa, parametrelerden birini kaldırın. Veri setimde değerler arasında güçlü bir ilişki yoktu.
4. Aykırı verileri veri kümesinden çıkarın
Aykırı değerler , diğer gözlemlerden uzak olan gözlem noktalarıdır. Mesela, verilerime göre 500 metrekarelik bir fiyata 50 metrekarelik bir ev vardı. Bu tür evler piyasada çeşitli nedenlerle mevcut olabilir, ancak istatistiksel olarak anlamlı değildir. Piyasa ortalamasını temel alarak bir fiyat tahmini yapmak istiyorum ve bu nedenle bu tür aykırı değerleri hesaba katmayacağım.
Çoğu regresyon yöntemi, aykırı değerlerin sonuçları önemli ölçüde etkileyebileceği için veri setinden açıkça çıkarılmasını gerektirir. Ayracı çıkarmak için aşağıdaki işlevi kullandım:
def get_outliners(dataset, outliers_fraction=0.25):
clf = svm.OneClassSVM(nu=0.95 * outliers_fraction + 0.05, kernel="rbf", gamma=0.1)
clf.fit(dataset)
result = clf.predict(dataset)
return result
Bu, aykırı durum için -1, aykırı olmayanlar için 1 olacaktır. Sonra böyle bir şey yapabilirsiniz:
training_dataset = full_dataset[get_outliners(full_dataset[analytics_fields_with_price], 0.15)==1]
Bundan sonra sadece dışlayıcı gözlemlere sahip olacaksın. Şimdi regresyon analizine başlama zamanı.
5. Bir regresyon algoritması seçin
Regresyon analizi yapmanın birden fazla yolu var. Aradığımız şey verilerimize verilen en iyi tahmin doğruluğu. Fakat doğruluğu nasıl kontrol edebiliriz? Yaygın bir yol, temelde gerçek ve öngörülen değer arasında kare bir fark olan r ^ 2 puanı hesaplamaktır .
Doğruluğumuzu öğrenmek ve kontrol etmek için aynı veri setini kullanırsak, modelimizin uygun olabileceğini hatırlamak önemlidir. Bu, belirli bir veri setinde mükemmel doğruluk göstereceği ancak yeni veriler verildiğinde tamamen başarısız olacağı anlamına gelir.
Bu sorunu çözmek için ortak bir yaklaşım, orijinal veri setini iki parçaya bölmek ve daha sonra bir öğrenme için bir diğeri test etmek için kullanmaktır. Bu şekilde, öğrenme modelimiz için yeni verileri simüle edeceğiz ve eğer bir kıyafet varsa, onu tespit edebiliriz.
Veri setimizi 80/20 oranını kullanarak bölebiliriz. Eğitim için% 80, test için geri kalan% 20 kullanacağız. Bu kod parçasına bir göz atalım:
// algoritma kalite tahmini için kod
from sklearn import svm
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsRegressor
from sklearn.linear_model import LinearRegression, LogisticRegression
from sklearn.svm import SVR
from sklearn.metrics import r2_score
from sklearn.cross_validation import train_test_split
from sklearn.ensemble import RandomForestRegressor
import pandas as pd
#prepare dataset
#....
#spilt dataset
Xtrn, Xtest, Ytrn, Ytest = train_test_split(training_dataset[analytics_fields], training_dataset[['price']],
test_size=0.2)
# model = RandomForestRegressor(n_estimators=150, max_features='sqrt', n_jobs=-1)
models = [LinearRegression(),
RandomForestRegressor(n_estimators=100, max_features='sqrt'),
KNeighborsRegressor(n_neighbors=6),
SVR(kernel='linear'),
LogisticRegression()
]
TestModels = pd.DataFrame()
tmp = {}
for model in models:
# get model name
m = str(model)
tmp['Model'] = m[:m.index('(')]
# fit model on training dataset
model.fit(Xtrn, Ytrn['price'])
# predict prices for test dataset and calculate r^2
tmp['R2_Price'] = r2_score(Ytest['price'], model.predict(Xtest))
# write obtained data
TestModels = TestModels.append([tmp])
TestModels.set_index('Model', inplace=True)
fig, axes = plt.subplots(ncols=1, figsize=(10, 4))
TestModels.R2_Price.plot(ax=axes, kind='bar', title='R2_Price')
plt.show()
Sonuç olarak, aşağıdaki grafiği aldım:
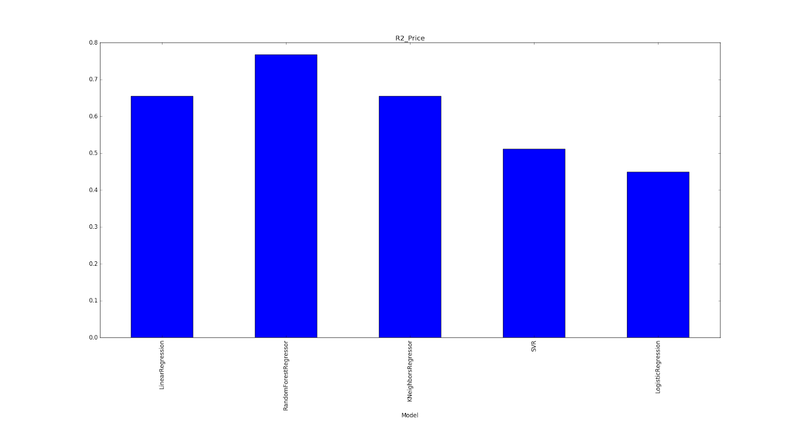
Gördüğünüz gibi,RandomForest regresör en iyi doğruluğu gösterdi, bu yüzden bu algoritmayı üretim için kullanmaya karar verdik.
Üretimdeki fiyat tahmini, test kodumuzdakiyle aynı şekilde çalışır, çünkü artık r ^ 2 hesaplamak ve modelleri değiştirmek gerekmez .
Bu noktada, uygun fiyat tahminleri sunabiliriz. Bir evin gerçek fiyatını bizim öngörülen fiyatımızla karşılaştırabilir ve sapmayı gözlemleyebiliriz.
Analiz ettiğim evleri düşük değerden aşırı değere kadar sıraladım. Bu yazılım sadece Sakarya'daki evleri sıralıyor.
Doğal olarak, ev fiyat tahmin algoritmam %100 doğru değil. Ama benim için kabul edilebilir çünkü ilk hedefim, bir ev almayı veya satmayı düşünen ve piyasadaki fiyatları karşılaştırmak isteyen insanlar için el ile yapılan iş miktarını azaltmak için bir tür özel sıralama oluşturmaktı.
